
Humans of the Data Sphere Issue #9 March 11th 2025
Your biweekly dose of insights, observations, commentary and opinions from interesting people from the world of databases, AI, streaming, distributed systems and the data engineering/analytics space.

Welcome to Humans of the Data Sphere issue #9!
Apologies for being almost 2 weeks late! I got really busy and I don’t do task switching.
First, some lyrics by Alabama Shakes that hit me this week. Most powerfully sung in the intro of this remix.
My life, your life
Don't cross them lines
What you like, what I like
Why can't we both be right?
Attacking, defending
Until there's nothing left worth winning
Your pride and my pride
Don't waste my time—Alabama Shakes
Also, out of curiosity, are you a Jeep or a Ferrari (see below)?
Quotable Humans
Joran Dirk Greef: Towards the D in ACID, how many DBMSs: - fsync() on commit - fsync() on opening the WAL - daisy chain checksums (cf. misdirected I/O) - open the WAL with O_DIRECT (cf. fsyncgate) - have 2 WALs (cf. Protocol-Aware Recovery) - don't trust the inode to get WAL size - test this?
Murat Demirbas: I am deeply skeptical of "hacks." There is no trick or unconventional approach that will quickly/magically improve your mastery. Nothing can replace the blood, sweat, and tears required to master any skill.
Rahul Jain: Apache Iceberg maintainers should probably read the 'Dont make me think' book.
Charity Majors: Tbh I'm not fond of the term "leader" bc it implies the existence of "followers". I prefer thinking about it in terms of agency and ownership, or autonomy and giving a shit. I've often jokingly said I owe my career to a lifelong overdeveloped sense of ownership.
After I became a manager, I started to realize what a relief it is to have people on your team who feel personally accountable and on the hook for things. It's one less thing you have to worry about, when you can trust someone else is already worrying about it.
Anders: Arrow is the unsung hero of this project (and arguably all innovation in data ecosystem).
Chris Riccomini: We built data catalogs, service catalogs, schema registries, and information_schemas. They're all catalogs, and they're all converging.
Chris Riccomini: I'm getting more and more excited about drop-in, frictionless infrastructure. Lots going on in observability, containers, cloud compute, etc. eBPF is part of it, so is monkey patching. Some interesting ones:
loopholelabs.io, polarsignals.com, junctionlabs.io ﹩, subtrace.dev ﹩
Joy Gao: For decades SQL Sages have been shaking heads at ORMs practitioners (impedance mismatch, N+1 queries, over-fetching of data, etc.). The SQL Sages also realize they can't change the devs' minds about ORMs (code has more programability after all), so they began to shift their focus on improving ORMs. The result is that ORMs kinda won in terms of interfaces. It became the magical layer that translates inefficient procedural code into db-optimized declarative SQL, performing fancy tasks like predicate pushdown, join optimizations, query deduping, caching, etc. Sounds familiar? oh yeah, because the database does all that too. So now we essentially depend on two abstraction layers to read/write data. It works most of the time, to the point we are willing to tolerate it when it blows up in our faces occasionally.
Murat Demirbas: A smart friend of mine put it perfectly. On his dream software team, he wants either Jeeps or Ferraris. Jeeps go anywhere. No roads, no directions—just point them at a problem, and they’ll tear through it. That’s effectual reasoning. Ferraris, on the other hand, need smooth roads and a clear destination. But once they have that, they move fast.
Murat Demirbas: I was young, naive, and plagued by impostor syndrome. I held back instead of exploring more, engaging more deeply, and seeking out more challenges. I allowed myself to be carried along by the current, rather than actively charting my own course. Youth is wasted on the young. Why pretend to be smart and play it safe? True understanding is rare and hard-won, so why claim it before you are sure of it? Isn't it more advantageous to embrace your stupidity/ignorance and be underestimated? In research and academia, success often goes not to the one who understands first, but to the one who understands best. Even when speed matters, the real advantage comes from the deep, foundational insights that lead there.
Mahesh Balakrishnan: System design has a core tenet that “complex things can be made simple with abstraction”. To a non-systems person, the complexity seems unavoidable, so often they just want you to get on with the job of shoveling the crap, instead of studying it contemplatively.
Geoffrey Litt: good designs expose systematic structure; they lean on their users' ability to understand this structure and apply it to new situations. we were born for this. bad designs paper over the structure with superficial labels that hide the underlying system, inhibiting their users' ability to actually build a clear model in their heads.
Ethan Mollick: A key to AI agents is an ability to self-correct. The world is full of odd errors and weirdness, and if AI can't recognize and problem-solve when it hits a wall, errors compound & the agent is useless. … This is why I don't actually buy the "agents will always fail because AI is unreliable" argument. It is possible to imagine solutions where they are self-correcting (but we aren't there yet).
Ethan Mollick: Wrappers often amaze people because they don’t realize how much the current LLMs can do. That doesn’t mean the current LLMs are flawless, but they have more latent capabilities than people think.
Joe Reis: In an age of fast delivery, does orthodoxy matter anymore? I strongly believe it does. If you understand orthodoxy, you know why you’d want to follow the rules. You also understand what rules to break and why. There are lots of rules that are worth following. Orthodoxy exists for a reason. It’s well established because people have invested time (often decades) and money into it, honing and shaping its imperfections over time, which implies it works for many people. The relational and dimensional models have been implemented in production across countless companies of all sizes and industries. For the 99% of companies out there, these modeling approaches will work.
Xiangpeng Hao with a thought provoking post on the future of academic systems research: System research is irrelevant. Industry has become the better place for meaningful systems work. Most impactful and innovative systems today come from companies, not universities. Industry has the money and patience to build complete systems. But most importantly, industry systems are accountable – systems that don’t deliver value get shut down quickly. This accountability creates a natural selection process. Industry systems must stay relevant or die. They evolve to meet real needs or disappear.
Viktor Kessler: Just as a physical product needs packaging, tracking labels, storage, customs clearance, and optimized transportation routes before it reaches its destination, data relies on metadata to be discoverable, accessible, secure, and compliant. Without metadata, data would be like a package without a label — unidentifiable, misrouted, or stuck in transit.
In global supply chains, logistics ensure that raw materials turn into finished products and are delivered efficiently. Likewise, metadata governs how data is structured, stored, accessed, and moved through pipelines, ensuring it reaches the right consumer — whether that’s an analyst, an AI model, or an automated system — without delays or integrity issues.
Just as supply chains don’t function without logistics, data ecosystems don’t function without actionable metadata.
Nicholas Gates, Joe Isaacs on Vortex file format capabilities: All columnar file formats support the idea of projection push-down. That is, only reading columns that are requested by the reader or are required to evaluate any filter predicates.
Most columnar file formats support the idea of predicate push-down. That is, using Zone Maps to prune large chunks of rows whose statistics provably fail the predicate. Vortex is unique in the way it evaluates filter and projection expressions by supporting full compute push-down, in many cases avoiding decompression entirely.
Stop treating ‘AGI’ as the north-star goal of AI research: Illusion of Consensus. Using shared term(s) in a way that gives a false impression of consensus about goals, despite goals being contested. The increasing popular use of the term “AGI” (Holland, 2025; Grossman, 2023; IBM, 2023) creates a sense of familiarity, giving the illusion that there is a shared understanding on what AGI is, and broad agreement on research goals in AGI development. However, there are vastly different opinions on what the term AGI refers to, what an AGI research agenda looks like, and what the goals in AGI development are. Left unchecked, this illusion obstructs explicit engagement on what the goals of AI research are and should be.
Hanson Ho: Write-time aggregation of metrics is a workaround you only do because the volume of data forces you to. If you have no such constraints, you're giving up all that delicious context for nothing. …The shift [to wide events] is fundamental bc it enables you to ask questions that you didn't anticipate when you instrumented, to figure out unknown unknowns. Picking dimensions to aggregate beforehand means you can monitor areas you already know is problematic - it doesn't allow the data to tell you things.
Katie Leonard: Tom DeMarco’s book Slack: Getting Past Burnout, Busywork, and the Myth of Total Efficiency was published in 2001, during the aftermath of the dotcom bubble. In it, he reflects on a familiar corporate restructuring trend—the “Year of Efficiency” that was the decade of the 1990s. His thesis is simple but powerful:
"Slack is the degree of freedom required to effect change."
Companies that strip out their middle management layer in the name of efficiency are not just cutting costs—they’re cutting their ability to adapt. Without slack, organizations become rigid. When everyone is constantly at capacity, no one has the bandwidth to innovate, reflect, or drive change.
Maksim Kita (from 2023 but I stumbled on it this week and it’s a nice overview): Hash tables require many design decisions at different levels and are subtly very complex data structures. Each of these design decisions has important implications for the hash table on its own but there are also ramifications from the way multiple design decisions play together. Mistakes during the design phase can make your implementation inefficient and appreciably slow down performance. A hash table consists of a hash function, a collision resolution method, a resizing policy, and various possibilities for arranging its cells in memory.
Tim Kellogg: My hottest take is that multi-agents are a broken concept and should be avoided at all cost. My only caveat is PID controllers; A multi agent system that does a 3-step process that looks something like Plan, Act, Verify in a loop. That can work.
Interesting topic #1 - Applying the Hierarchy of Controls to software
In his post, The Hierarchy of Hazard Control, Hillel Wayne introduces the Hierarchy of Control concept, taken from the world of mechanical engineering.

Hillel asks “Can we use the Hierarchy of Controls in software engineering?” and goes on to recount his classic experience of being the developer that dropped the production database (many of us have been there).
About ten years ago I was trying to debug an issue in production. I had an SSHed production shell and a local developer shell side by side, tabbed into the wrong one, and ran the wrong query.
That’s when I got a new lesson: how to restore a production database from backup.
He then goes on to explain how using the Hierarchy of Controls (HoC), could have avoided this unfortunate incident. For example, for substitution, Hillel writes:
For our problem I can see a couple of possible substitutions. We can substitute the production shell for a weaker shell. Consider if one “production” server could only see a read replica of the database. Delete queries would do nothing and even dropping the database wouldn’t lose data. Alternatively, we could use an immutable record system, like an event source model. Then “deleting data” takes the form of “adding deletion records to the database”. Accidental deletions are trivially reversible by adding more “undelete” records on top of them.
I recommend the rest of the post, as it provides a new way of thinking about how we can put measures in place to avoid those nasty accidents in production. For my part, I dropped the production database on my first job, in a similar sequence of events.
Interesting topic #2—Data Virtualization
Virtualization is top of mind for me at the moment. I wrote Towards Composable Data Platforms which argues that the table formats enable platform composability due to how they enable table virtualization.
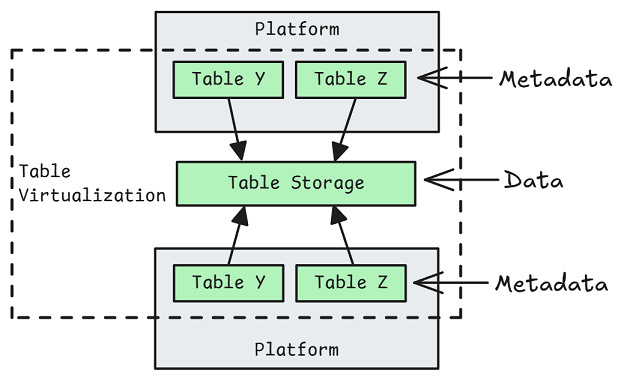
Virtualization in software refers to the creation of an abstraction layer that separates logical resources from their physical implementation. The abstraction may allow one physical resource to appear as multiple logical resources, or multiple physical resources to appear as a single logical resource.
At every layer of computing infrastructure - from storage arrays that pool physical disks into flexible logical volumes, to network overlays that create programmable topologies independent of physical switches, to device virtualization that allows hardware components to be shared and standardized - virtualization provides a powerful separation of concerns. This abstraction layer lets resources be dynamically allocated, shared, and managed with greater efficiency.
At the heart of data virtualization is the separation of data storage from metadata that describes it, how to access it, statistics about it and so on. With this separation, we can use metadata to present virtualized forms of the same underlying data, to different users, and even surfaced on different platforms.
Virtualization is something we’ve been working on at Confluent. In fact, this issue of HOTDS is late because I’ve been head down working on writing both internal documentation for engineering teams but also a public facing deep dive for a new partition virtualization architecture we are slowly bringing to production to power our serverless workloads. If you find the topic of data virtualization interesting then stay tuned, myself and some Confluent engineers will be posting a deep dive about it soon.