
Humans of the Data Sphere Issue #5 December 10th 2024
Your biweekly dose of insights, observations, commentary and opinions from interesting people from the world of databases, AI, streaming, distributed systems and the data engineering/analytics space.

Welcome to Humans of the Data Sphere issue #5!
First, a Haiku for Cloudflare:
One small adjustment,
Tides of load come rushing in,
Servers gasp, then sink.
Best meme:
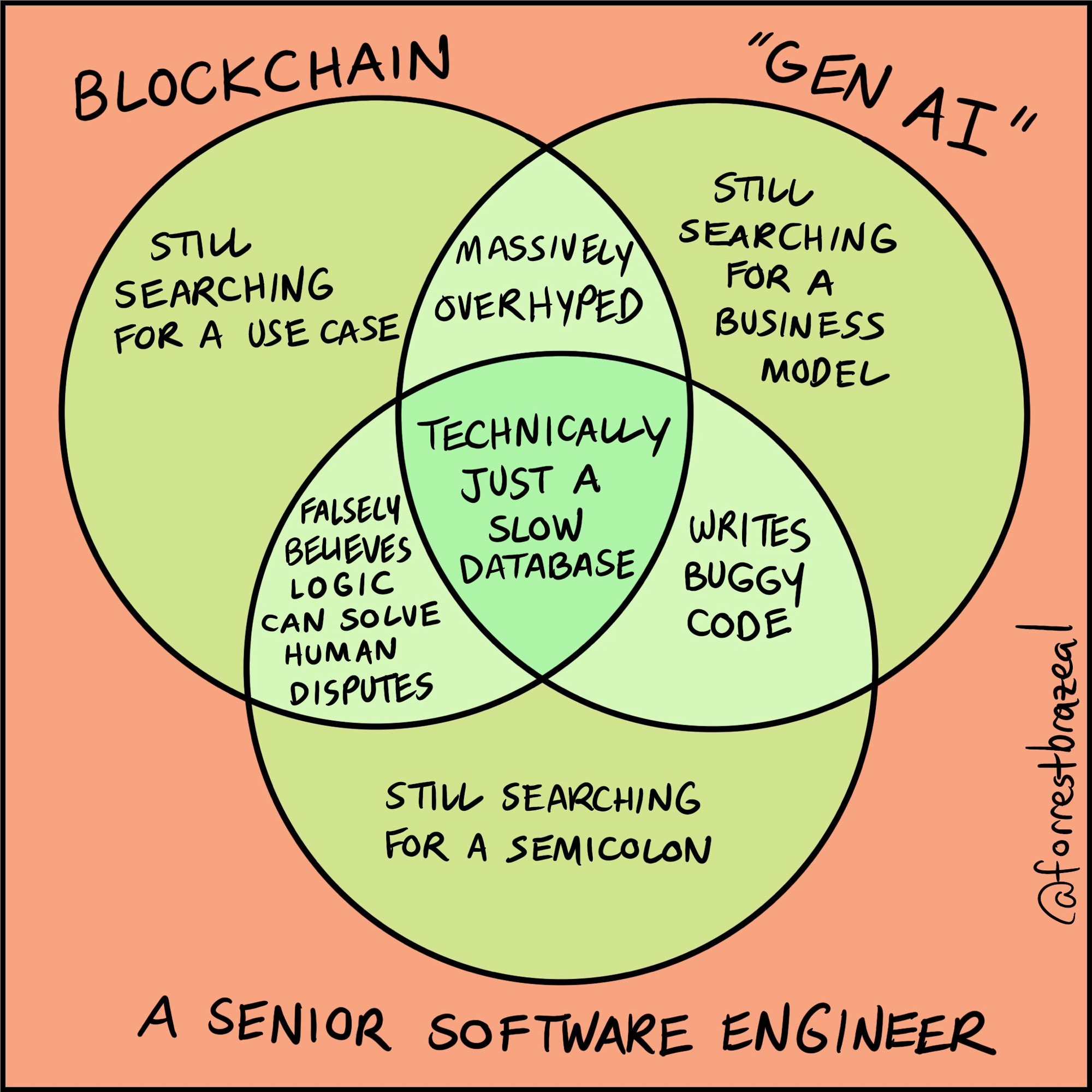
Quotable Humans
Craig Kerstiens (quoting a comment on HN about Aurora DSQL limitations): "Postgres compatible" - No views/triggers/sequences - No foreign key constraints - No extensions - No NOTIFY ("ERROR: Function pg_notify not supported") - No nested transactions - No JSONB. What, what IS it compatible with?
Gunnar Morling: I think it's about time we get a TCK which asserts what "Postgres compatible" means. Like, you need to have sequences, foreign key constraints, views, etc. in order to be able to claim that.
DBA: Something like this? Postgres compatibility index "alpha version" https://github.com/secp256k1-sha256/postgres-compatibility-index/tree/main/postgres-compatibility-index
Daniel Beach: AWS S3 Tables?! The Iceberg Cometh. weep moan, wail all ye Databricks and Snowflake worshipers
Chris Riccomini: Lot's of interesting stuff happening in filesystem-on-object storage these days. regattastorage.com had a splashy YC launch, we have juicefs.com and alluxio.io, and been hearing about national labs using gluster.org & ceph.io. Seems like market is growing for these offerings.
Sriram Subramanian: Vector database companies will become one of the three
a. Search platforms (e.g., Elastic)
b. AI platform (inference/training/pipeline)
c. OLTP provider (e.g., MongoDB, Postgres)
Hard for vector databases to be a separate offering/company
JD Long: I have a kick ass quality engineering lead. She taught me about including QE folks in design so things get built easier to test. And about getting QE involved in logging & monitoring. We’re calling it “shift left and right” which we should probably turn into a dance at the firm Christmas party.
Alex Miller (made some notes on disaggregated OLTP Systems):
Socrates feels like a very modern object storage-based database in the WarpStream or turbopuffer kind of way for it being a 2019 paper. This architecture is the closest to Neon’s as well.
Thus, much of the PolarDB Serverless paper is about leveraging a multi-tenant scale-out memory pool, built via RDMA. This makes them also a disaggregated memory database! As a direct consequence, memory and CPU can be scaled independently, and the evaluation shows elastically changing the amount of memory allocated to a PolarDB tenant. However, implementing a page cache over RDMA isn’t trivial, and a solid portion of the paper is spent talking about the exact details of managing latches on remote memory pages and navigating b-tree traversals.
Kelly Sommers: One thing I really notice coming back to C#/.NET space is many have been taught to value style over sound engineering. Given a task to build a report over millions of rows & apply a custom calc to each row they will do this all in C#. Resisting SQL & sprocs 500K round trips. [This post triggered quite a lively discussion]
Personal note (Jack): Back in the days of C# 3, I rewrote a C# batch job written in this style, replacing it with a stored procedure, reducing running time from 24 hours to 11 seconds. It was my first week on the job and the DBA was thankful but the architect was not. We made a truce and the SP was still there 5 years later when I moved on.
Mohit Mishra: CPU vs FPGA - what an easy and well explanation in 25 seconds. [It’s a cool visualization]
Air Katakana: what looks like “ai stealing jobs” to most people should look like “ai giving massive amount of leverage to individuals with high agency” to you
Anthony Goldbloom: My Kaggle experience suggests more than 75% of the machine learning models in production or written up in academic papers are overfit. Kaggle has strong controls on overfitting: - limited number of daily submissions - models were retested on a second test dataset that participants never received feedback on Under these conditions, a very high fraction of first-time competition participants would overfit to the public leaderboard set. And their position would drop dramatically when we retested their model on a second test dataset. This was true for experienced machine learners in academia and industry (not just newbies). The Kaggle controls are not imposed on data scientists for internal company projects or academic research.
Gergely Orosz: There's this evergreen joke on software development that goes something like this: "We're done with 90% of the project. Which means we only have the other 90% left to go." It's funny because it's true. It's also why experienced engineers are in-demand: they are the "finishers."
Lorin Hochstein: The resilience engineering research David Woods uses the term saturation in a more general sense, to refer to a system being in a state where it can no longer meet the demands put upon it. The challenge of managing the risk of saturation is a key part of his theory of graceful extensibility.
It’s genuinely surprising how many incidents involve saturation, and how difficult it can be to recover when the system saturates.
Reuben Bond (interesting discussion thread): CRDTs fit a system model that has hardly any overlap with datacenter-based applications. If I'm wrong, please point to datacenter-based apps which have benefited from the application of CRDTs.
Nikhil Benesch (on S3 Iceberg tables): Compaction costs are more of a mixed bag. For analytic workloads that write infrequently, they also look to be immaterial. But for streaming workloads that write frequently (say, once per second, or once per every ten seconds), compaction costs may be prohibitive. The cost per object processed looks tolerable (writing an object per second results in only 2.5MM objects per month that need to be compacted), but write amplification will be severe, and the cost per GB processed is likely to add up. To really get a sense for compaction costs, someone will need to run some experiments. A lot depends on how often S3 chooses to compact data files for a given workload, which is not something that’s directly under the user’s control.
Justin Jaffray (discusses extremely accurate data center clocks): To the best of my knowledge, despite being a concept in the realm of consistency, the "clock trick" is only really necessary in a distributed transactional database, which is why we've only really seen it in Spanner and now DSQL, and it has an important connection to multi-version concurrency control (MVCC).
…
Now, the magic clocks are not perfect, they're not accurate to like, Planck time, or something. But they come with a guarantee that no two of them disagree by more than some bound. That is, when a server observes the time to be
t, it knows that no other server will observe the time to be earlier than, say,t-100. The clocks of all the participants in the system are racing along a timeline, but there's a fixed-size window that they all fall within. This guarantee can be used to prevent the situation we described above. The guarantee we want is that once an operation finishes, no other operation will be ordered before it ever again.Murat Demirbas: I have been impressed by the usability of TLA-Web from Will Schultz. Recently I have been using it for my TLA+ modeling of MongoDB catalog protocols internally, and found it very useful to explore and understand behavior. This got me thinking that TLA-Web would be really useful when exploring and understanding an unfamiliar spec I picked up on the web.
To test my hunch, I browsed through the TLA+ spec examples here, and I came across this spec about the Naiad Clock. Since I had read DBSP paper recently, this was all the more interesting to me. I had written about Naiad in 2014, and about dataflow systems more broadly in 2017.
Dipankar Mazumdar: Adopting these table formats has laid the groundwork for openness. Still, it is crucial to recognize that an open data architecture needs more than just open table formats—it requires comprehensive interoperability across formats, catalogs, and open compute services for essential table management services such as clustering, compaction, and cleaning to also be open in nature.
Gunnar Morling (on Postgres 17 failover slots): Prior to Postgres version 16, read replicas (or stand-by servers) couldn’t be used at all for logical replication. Logical replication is a method for replicating data from a Postgres publisher to subscribers. These subscribers can be other Postgres instances, as well as non-Postgres tools, such as Debezium, which use logical replication for change data capture (CDC). Logical replication slots—which keep track of how far a specific subscriber has consumed the database’s change event stream—could only be created on the primary node of a Postgres cluster.
…
But the good news is, as of Postgres version 17, all this is not needed any longer, as it finally supports failover slots out of the box!
Charity Majors (on architects):
I think that a lot of companies are using some of their best, most brilliant senior engineers as glorified project manager/politicians to paper over a huge amount of organizational dysfunction, while bribing them with money and prestige, and that honestly makes me pretty angry.
Most of the pathologies associated with architects seem to flow from one of two originating causes:
unbundling decision-making authority from responsibility for results, and
design becoming too untethered from execution (the “Frank Gehry” syndrome)
But it’s only when being an architect brings more money and prestige than engineering that these problems really tend to solidify and become entrenched.
This is also why I think calling the role “architect” instead of “staff engineer” or “principal engineer” may itself be kind of an anti-pattern.
Marc Brooker (discussing how various technologies came together to make DSQL possible):
The second was EC2 time sync, which brings microsecond-accurate time to EC2 instances around the globe. High-quality physical time is hugely useful for all kinds of distributed system problems. Most interestingly, it unlocks ways to avoid coordination within distributed systems, offering better scalability and better performance. The new horizontal sharding capability for Aurora Postgres, Aurora Limitless Database, uses these clocks to make cross-shard transactions more efficient.
The third was Journal, the distributed transaction log we’d used to build critical parts of multiple AWS services (such as MemoryDB, the Valkey compatible durable in-memory database4). Having a reliable, proven, primitive that offers atomicity, durability, and replication between both availability zones and regions simplifies a lot of things about building a database system (after all, Atomicity and Durability are half of ACID).
The fourth was AWS’s strong formal methods and automated reasoning tool set. Formal methods allow us to explore the space of design and implementation choices quickly, and also helps us build reliable and dependable distributed system implementations6. Distributed databases, and especially fast distributed transactions, are a famously hard design problem, with tons of interesting trade-offs, lots of subtle traps, and a need for a strong correctness argument. Formal methods allowed us to move faster and think bigger about what we wanted to build.
Hugo Lu: Which leads to this “Data Observability Paradox” — although they claim to solve data quality they cannot. They can tell you where the problem is, but they do not solve the root cause. Indeed, the root cause is solved by having robust infrastructure (ingestion, orchestration, alerting etc) but most commonly, individuals not caring enough about the data. A cultural problem — not one that can be solved with Software.
David Jayatillake: Let’s start with a TLDR; Medallion Architecture is not a form of data modeling. It is associated with data modeling, and data modeling happens within it … I would prefer naming like staging, model and presentation. This is much closer to what people already know and expresses what actually happens in the layers. Bronze, silver and gold make it easier to explain to non-technical users. That’s the only reason why the product marketers have gone for Medallion architecture, although whether non-technical users really need to understand “how the sausage is made” is another question.
Ethan Mollick (suggestions on when and when not to use AI, I took one of each):
When: Work where you need a first pass view at what a hostile, friendly, or naive recipient might think.
When not: When the effort is the point. In many areas, people need to struggle with a topic to succeed - writers rewrite the same page, academics revisit a theory many times. By shortcutting that struggle, no matter how frustrating, you may lose the ability to reach the vital “aha” moment.
Interesting topic #1: Another incident, another config change
I loved Lorin Hochstein's “quick takes“ of Cloudflare's November 14, 2024, incident (which led to log data loss). Beyond that it was triggered by a config change, the post highlights several recurring patterns in system failures.
Saturation and Overload
Safety Mechanisms Backfiring
Complex Interactions and Latent Bugs
It’s a great read, with references to:
Brendan Gregg’s USE method that has shaped my own approach to running and monitoring distributed data systems.
David Woods' Theory of Graceful Extensibility [download from here] (which explores how complex systems adapt to increasing demands or pressures beyond their designed capacity, focusing on their ability to stretch and evolve rather than collapse under stress).
Lorin’s own work on safety mechanisms (such as his blog post A Conjecture on Why Reliable Systems Fail).

He also discusses the tension between automated recovery and the additional complexity that such systems introduce.
Interesting topic #2: So many data modeling methodologies (for warehousing)
TIL of Activity Schema, which I hadn’t heard of before, so I wondered if there were more (data warehousing) data modeling methodologies I didn’t know of, and what were the differences?
Here is a summary (feel free to curse me for my summarization choices). Later are some links to bloggers and practitioners that explore these modeling methodologies in far more detail.
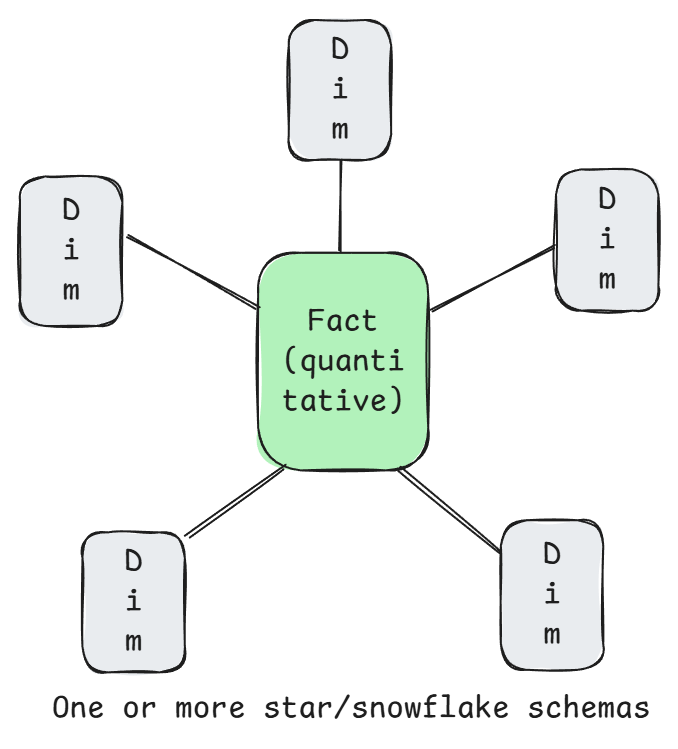
Dimensional modeling (Kimball)
Needs little introduction. Arranges data into fact tables (quantitative pieces of data such as sales amounts, units sold) and dimension tables for descriptive attributes (customer, product, location, time). Forms a star or snowflake schema. Optimized for BI.
Pros: Great for users to understand and write analytical queries against. The star schema reduces the need for complex joins, which can be expensive.
Cons: Not super flexible. Not so great at fast changing transactional data.

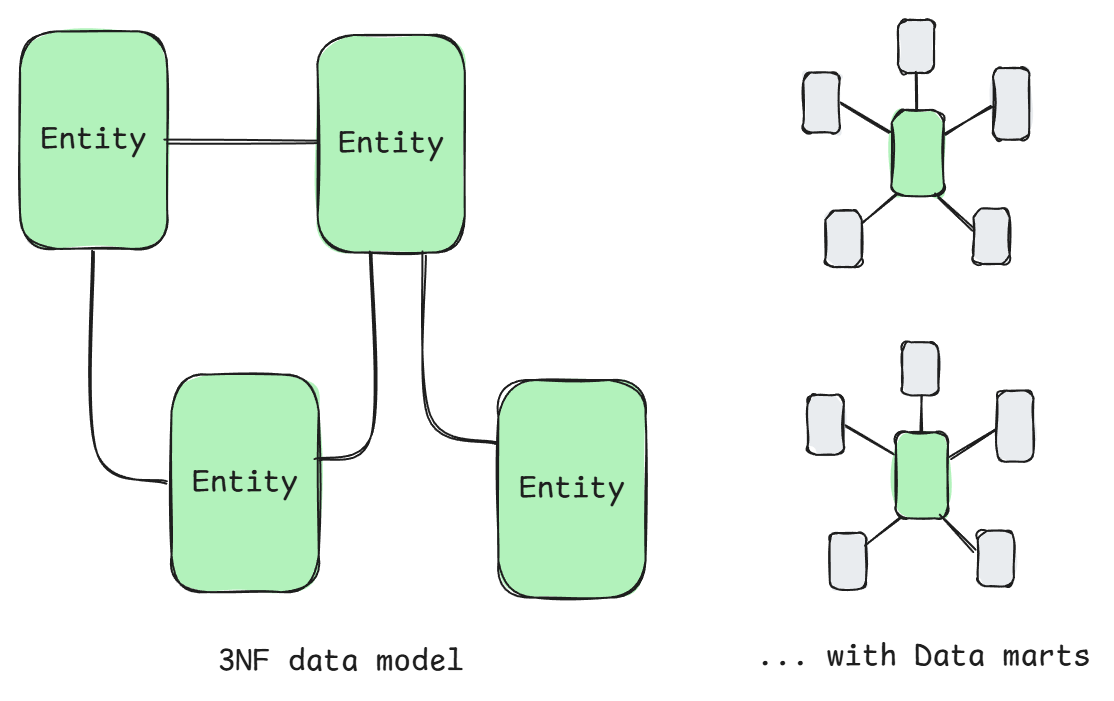
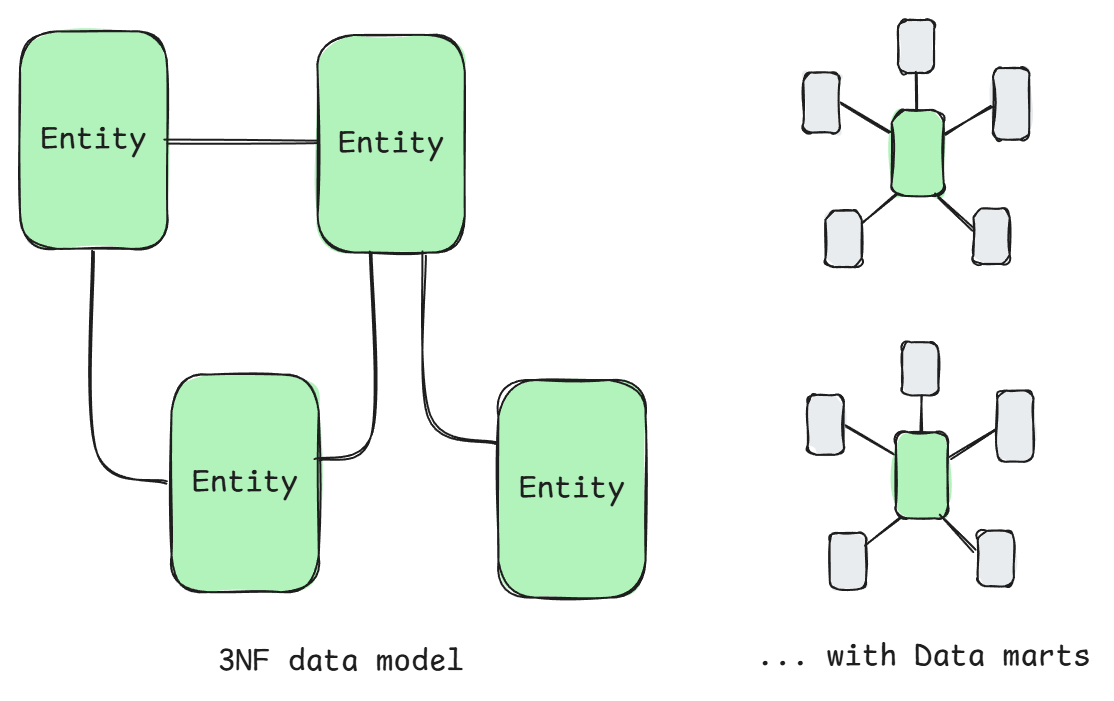
Normalized modeling (Inmon)
Focuses on creating a centralized, normalized enterprise data warehouse in Third Normal Form (3NF) to serve as a single source of truth for the organization, with a focus on consistency. Data from multiple source systems is integrated into a unified structure.
Pros: Great for data quality as well as integration with other systems as the data model is optimized for consistency and logical organization (rather than optimized for a specific workload like dimensional modeling is).
Cons: Relies on data marts as query performance is poor (think of a data mart as a business unit specific DW tailored to a more focused use case). Seems like a lot more work to maintain this organization-wide data model.
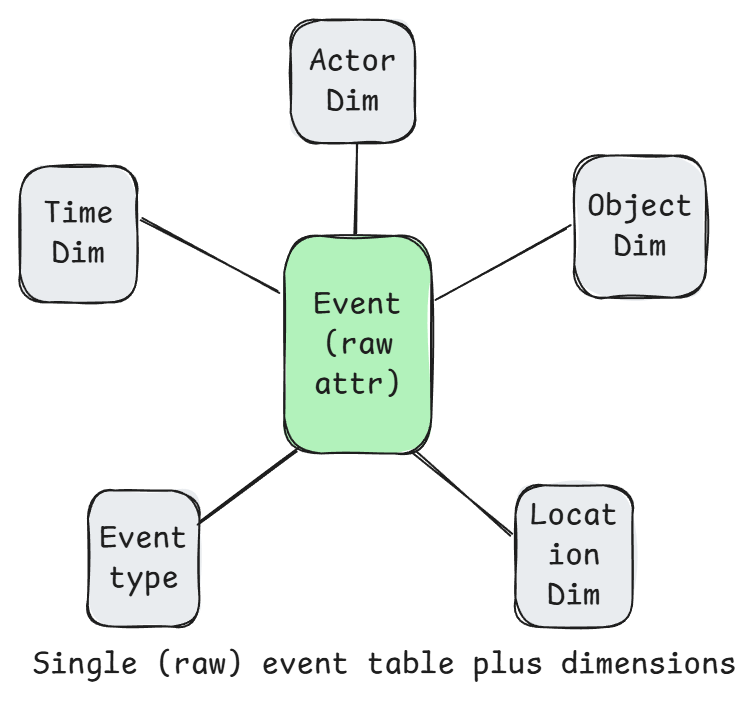
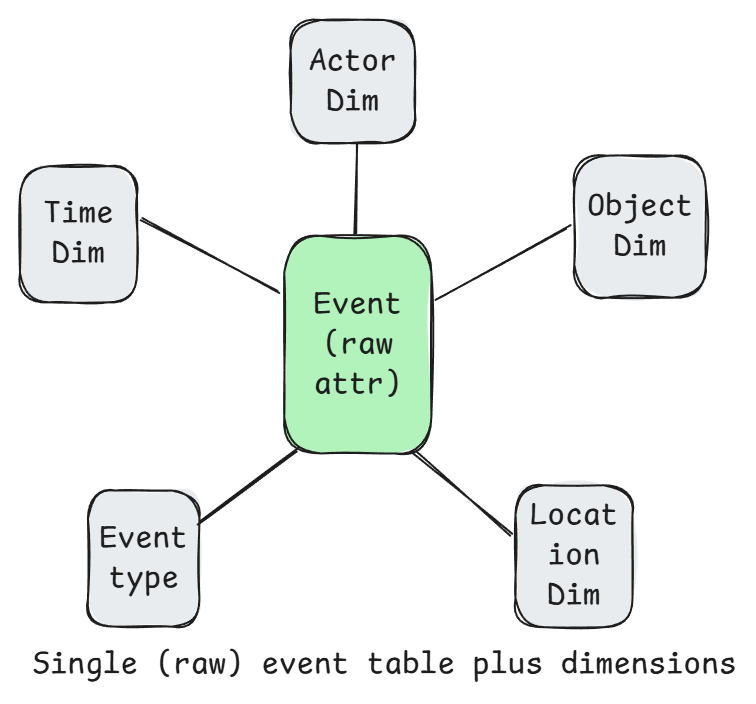
Event-centric modeling (Activity Schema)
Focuses on capturing and organizing data around events or activities (e.g., a purchase, login, or page view) and storing them in a single central activity table known as the activity stream. v2 allows for one table per activity. Each activity has a number of attributes that it is authoritative on, such as the web page visited, or value of the purchase etc. Activities in this single table are differentiated by an activity type string column. Each activity can optionally be linked to one or more entities (dimensions), such as the subject of the activity (the product purchased) or the actor (the user who did the purchase), or the location, and so on.
Pros: With a shared event table, it is great for understanding actions over time, such as tracking user behavior, system logs, IoT data, or transactions. Captures raw detailed data that supports deep and flexible analysis.
Cons: Can be challenging computationally (and storage) due to high cardinality of raw event data. Analytical queries involving joins or aggregations on high-cardinality columns (e.g., aggregating data by user, session, or time) can be slow and resource-intensive. Maintaining indexes can be challenging. High cardinality is a natural consequence of storing detailed, event-level data. There are a number of optimization techniques to mitigate these high-cardinality issues (e.g. data partitioning, aggregation, moving some attributes into dimensions, sampling, multiple activity stream tables etc).
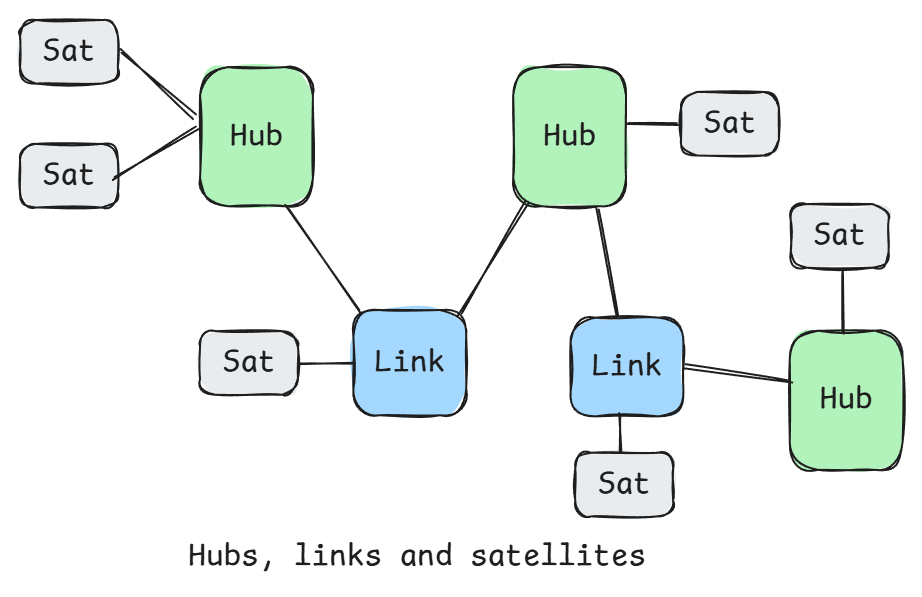
Data Vault
Organizes data into three core components: hubs, links, and satellites. Hubs store the unique business keys (e.g., customer IDs, product IDs) representing core business entities. Links capture the relationships between these hubs (e.g., which customer placed which order) and support many-to-many relationships. Satellites store the descriptive attributes of hubs and links. All store metadata for load timestamps and source system identifiers. Satellites enable an append-only approach as changes to attributes are simply appended, rather than overwriting, enabling detailed historical tracking and auditability. No need for Slowly Changing Dimensions (SCD).
Pros: The modular and append-only design makes it easier to maintain incrementally, and even by different teams. It is highly flexible to change and schema evolution. It’s historical tracking is ideal for highly regulated environments.
Cons: Queries are more complex (and expensive) than say dimensional modeling. It is also a less intuitive data model for users and analysts, so there may be some reliance on data marts. Due to its quite different data model, there is an associated learning curve though there is some Data Vault support in tooling to help.

Anchor modeling
It has some similarities with Data Vault, as it focuses on separating core entities (anchors) from their attributes as well as relationships between entities (known as ties). However, anchor modeling is more highly normalized and is less focused on auditability than Data Vault, with a stronger focus on adaptability and schema evolution. One of the primary goals of Anchor Modeling is to support schema flexibility and evolution without disrupting existing structures. Therefore each attribute gets its own table, new attributes can be added without modifying existing tables, ensuring non-disruptive schema updates. This is a more extreme level of normalization than other methodologies. New attributes or relationships can be added without altering existing tables. Schema changes are handled as non-disruptive extensions. Each attribute and tie table track historical changes using validity period columns (ValidFrom, ValidTo), enabling point-in-time analysis.
Pros: Very adaptable to change. Good support for historical analysis and point-in-time queries.
Cons: Similar to Data Vault, except there is less support in tooling. Due to the one-table-per-attribute, there can be more joins.

Wide-table / One Big Table (OBT) modeling
Combines data from multiple sources into a denormalized single table.
Pros: Great for read performance, no joins required. Practical - especially when you are using a columnar storage system such as ClickHouse, Snowflake, BigQuery etc. Even better if it can be maintained via pre-aggregation.
Cons: Not flexible. Harder to maintain as data shape changes. Harder to keep consistent.

These methodologies also cover more than just data modeling, such as how data goes through stages of processing and how data is queried from BI tools.
There are a number of people who write about this stuff (not an exhaustive list):
Joe Reis and his Practical Data Modeling substack
Simon Späti, who maintains his Second Brain, with plenty of content on data modeling.
Kent Graziano writes a lot about Data Vault.
Hans Hultgren also writes a lot about Data Vault.
Dave Wells writes about data modeling and data management in general.