
Humans of the Data Sphere Issue #3 November 12th 2024
Your biweekly dose of insights, observations, commentary and opinions from interesting people from the world of databases, AI, streaming, distributed systems and the data engineering/analytics space.

Welcome to Humans of the Data Sphere issue #3! Another whirlwind tour of what humans are saying across the data sphere, plus a quick-dive and survey of the interesting topic of compute-compute separation.

Quotable Humans
Jepsen: Last year we reported that MySQL and MariaDB's "Repeatable Read" was badly broken. The MariaDB team has been hard at work, and they've added a new flag, `--innodb-snapshot-isolation=true`, which causes "Repeatable Read" to prevent Lost Update, Non-repeatable Read, and violations of Monotonic Atomic View. It looks like MariaDB might, with this setting, offer Snapshot Isolation at "RR". :-)
Anton: There's a clear trend to migrate from Avro to Protobuf for streaming pipelines. This presentation by Uber was a great example. They showed several improvements they are contributing to Flink to make it possible: https://www.flink-forward.org/berlin-2024/agenda#streamlining-real-time-data-processing-at-uber-with-protobuf-integration
I think the main benefit is to use the same format everywhere. That was the reason for Uber, and it would be the same for New Relic (used in OpenTelemetry) if we fully migrate at some point.
Chris Riccomini: Even if a company wanted to use DuckDB as their data warehouse, they couldn’t. DuckDB can’t handle the largest queries an enterprise might wish to run. MotherDuck has rightly pointed out that most queries are small. What they don’t say is that the most valuable queries in an organization are large: financial reconciliation, recommendation systems, advertising, and others. These are the revenue drivers. They might comprise a minority of all the queries an organization runs, but they make the money.
Pranav Aurora: pg_mooncake builds on this by introducing a native columnstore table to Postgres–supporting inserts, updates, joins, and soon, indexes. These tables are written as Iceberg or Delta tables (parquet files + metadata) in your object store. It leverages pg_duckdb for its vectorized execution engine and deploys it as a part of the extension.
Jake Thomas: (in the context of rising use of object storage): Once upon a time we pulled data out of prod databases and put it in larger/olap/dedicated stores/DW's for pretty much one reason: running analytical queries was too slow/impactful to prod infra. That reasoning is becoming less valid, which makes one rethink if the complexity/cost is worth it.
Jacob Matson: which means that basically every bit of compute & storage could be intermediated by a catalog... in theory it also means that your catalog could shop queries coming from a generic endpoint to the cheapest engine for that specific query.
Kostas Pardalis: There are two types of consumers of a catalog. Humans and machines and they are very different. There’s a lot of engineering going on in scaling catalogs for systems like Snowflake and a folder plus some lineage does not suffice.
Unstable organizational priorities lead to meaningful decreases in productivity and substantial increases in burnout, even when organizations have strong leaders, good internal documents, and a user-centric approach to software development.
Optimistically, and consistent with our findings that AI has positively
impacted development professionals’ performance, respondents reported that
they expect the quality of their products to continue to improve as a result of AI over the next one, five, and 10 years. However, respondents also reported
expectations that AI will have net-negative impacts on their careers, the environment, and society, as a whole, and that these negative impacts will be
fully realized in about five years time.
Developers are more productive, less prone to experiencing burnout, and more likely to build high quality products when they build software with a user-centered mindset. … This approach gives developers confidence that the features they are working on have a reason for being. Suddenly, their work has meaning: to ensure people have a superb experience when using their products and services. There’s no longer a disconnect between the software that’s developed and the world in which it lives.
Jeremy Morrell (on wide events/o11y 2.0): Nope, these are all old ideas, but I’d argue that this is very unevenly understood / adopted across industry. Responses to my post generally fall into “I’ve never heard of this kind of approach before” or “we’ve been doing this for a decade+” with very little in between
Reuben Bond: Raft was optimized for understandability over simplicity 🤷 Chris Jensen & @heidihoward.bsky.social wrote about LogPaxos, which they say is simpler than Raft or MultiPaxos: https://decentralizedthoughts.github.io/2021-09-30-distributed-consensus-made-simple-for-real-this-time/. CASPaxos is simpler but likely less broadly applicable than log-based consensus
Peter Corless: There's still a lot of work to put into all of this. But the worlds of Observability and real-time analytics are on a collision course.
A. Jesse Jiryu Davis and Matthieu Humeau (on predictive scaling):
This means servers can be overloaded or underloaded for long periods! An underloaded server is a waste of money. An overloaded server is bad for performance, and if it’s really slammed it could interfere with the scaling operation itself.
The Forecasters and Estimator cooperate to predict each replica set’s future CPU on any instance size available. E.g., they might predict that 20 minutes in the future, some replica set will use 90% CPU if it’s on M40 servers, and 60% CPU if it’s on more powerful M50 servers.
Our goal is to forecast a customer’s CPU utilization, but we can’t just train a model based on recent fluctuations of CPU, because that would create a circular dependency: if we predict a CPU spike and scale accordingly, we eliminate the spike, invalidating the forecast. Instead we forecast metrics unaffected by scaling, which we call “customer-driven metrics”, e.g. queries per second, number of client connections, and database sizes. We assume these are independent of instance size or scaling actions. (Sometimes this is false; a saturated server exerts backpressure on the customer’s queries. But customer-driven metrics are normally exogenous.)
Ludicity: The word enterprise means that we do this in a way that makes people say "Dear God, why would anyone ever design it that way?", "But that doesn't even help with security" and "Everyone involved should be fired for the sake of all that is holy and pure."
Gunnar Morling: (on the outbox pattern)
If you want to achieve consistency in a distributed system, such as an ensemble of cooperating microservices, there is going to be a cost. This goes for the outbox pattern, as well as for the potential alternatives discussed in the next section. As such, there are valid criticisms of the outbox pattern, but in the end it’s all about trade-offs: does the outbox put an additional load onto your database? Yes, it does (though it usually is insignificant, in particular when using a log-based outbox relay implementation). Does it increase complexity? Potentially. But this will be a price well worth paying most of the time, in order to achieve consistency amongst distributed services.
While alternatives do exist, they each come with their own specific trade-offs, around a number of aspects such consistency, availability, queryability, developer experience, operational complexity, and more. The outbox pattern puts a strong focus on consistency and reliability (i.e. eventual consistency across services is ensured also in case of failures), availability (a writing service only needs a single resource, its own database) and letting developers benefit from all the capabilities of their well-known datastore (instant read-your-own-writes, queries, etc.).
Han Lee: In Thinking, Fast and Slow, Daniel Kahneman defined System 1 as the automatic, intuitive mode of thinking, and System 2 as the slower, more analytical mode. In the context of autoregressive language models, the usual inference process is akin to System 1 — models generate answers directly. Reasoning is System 2 thinking - models or systems takes time to deliberate to solve more complex problems.
Josh Willis: The fact that DuckDB isn't a data warehouse...is the whole point of DuckDB! Once you pull your head out of the snow or the bricks or wherever you spend most of your data engineering time, you will discover that there are data pipeline problems *everywhere* that benefit from data modeling and SQL!
Josh Willis: too often, folks say "data quality problem" when they mean "we don't have a good way to collaborate with our upstream dependencies" or more directly "we hate the frontend and backend engineering teams, they don't care about data"
Julia Evans: I feel like half of programming is remembering how weird stuff works and the other half is setting things up so that you do not have to remember the weird stuff
Lutz Hühnken: Did you ever realize that when data engineers look at events, they see them differently than Event-Driven Architecture / Domain-Driven Design folks?
Jake Thomas: all these people be talking about ai, zero disk architectures, and open table formats while I'm giddily stuffing DuckDB into Prometheus exporters 🤷♂️🤷♂️🤷♂️ https://github.com/jakthom/hercules
Ryanne Dolan: BigTech is moving to object storage too, but not cuz it's cheaper. The idea is you no longer need every system to be distributed and durable. Everything can be stateless and simple, cuz your storage is distributed and durable.
Kenneth Stanley: Two things that both evolution and neural networks share in common is they both thrive on scale, and they were both once dismissed as obsolete to AI. The deep evolution moment is awaiting.
François Chollet: Similarly, there are several research directions today seen as long-abandoned failures, that are only waiting for the right amount of attention and the right level of compute scale to shine. Genetic algorithms are one of them.
Ethan Mollick: I keep hearing from executives that they expect that a new generation of "AI natives" will show them how to use AI. I think this is a mistake: 1) Our research shows younger people do not really get AI or how to integrate into work 2) Experienced managers are often good prompters
Ethan Mollick: We are just not used to abundant "intelligence" (of a sort), which leads people to miss a huge value of AI. Don't ask for an idea, ask for 30. Don't ask for a suggestion on how to end a sentence, ask for 20 in different styles. Don't ask for advice, ask for many strategies. Pick
Shreya Shankar: Whenever I talk to ML/AI researchers, many are surprised that complex and long document processing with LLMs is so hard. I find it strange how little attention (comparatively) is given to this, given that data processing probably has the highest market cap of all applications
Soumil S: In my experiment, I set up two types of tables—managed Iceberg tables registered via Polaris within Snowflake, and unmanaged Iceberg tables also registered via Polaris. I attempted to join these tables in both Snowflake and Spark, with mixed results: while Snowflake handled the join seamlessly, Spark wasn’t able to join the internal and external catalogs. To me, this feels like a potential limitation, as Spark doesn’t support joining across internal and external catalogs registered through Polaris.
Vikram Singh Chandel: hmm interesting, so strategically we should not only work on Iceberg as a unified format but a unified catalog that does not limit vendor-specific features
Roy Hasson: That's expected behavior. If you make both tables external they can be joined by external engines. If you make them internal/managed then really only snowflake can join them. It's unfortunate, but that's the behavior and why internal/managed tables are a bit of a lock-in.
Weston Pace: Whenever we talk about backpressure we also often talk about push vs. pull. In a push-based system a producer creates and launches a task as soon as data is available. This makes parallelism automatic but backpressure is tricky. In a pull-based system the consumer creates a task to pull a batch of data and process it. This makes backpressure automatic but parallelism is tricky. The reality is that every multi-threaded scanner / query engine is doing both push and pull somewhere if you look hard enough.
Katie Bauer: It's 2024.
LinkedIn overflows with thought leaders proclaiming AI will get better and cheaper, if we just wait 6 months.
Data quality is still a mess, despite insistence that AI will finally justify investments.
Sparkles are stamped on UIs everywhere, ruining a perfectly good emoji.
Julien Le Dem: A query engine reduces the cost of scanning columnar data in a few ways:
Projection push down: By reading only the columns it needs.
Predicate push down: * By skipping the rows that it doesn’t need to look at. This typically leverages embedded statistics. * By better skipping ahead while decoding values. Simply by leveraging understanding the underlying encodings. Skipping in Run Length Encoding or fixed width encodings is really cheap.
Vectorization: By using vectorized conversion from the on-disk Parquet columnar representation to the in-memory Arrow representation.
Ross Wightman: Utilization is a poor metric by itself. You can easily hit 100% where the GPU is doing a lot of waiting. Power consumption is a better (but not perfect) measure. If you're burning watts it's usually doing something useful. High util, no watts is not good.
Alex Miller: Regardless of using buffered or unbuffered IO, it’s wise to be mindful of the extra cost of appending to a file versus overwriting a pre-allocated block within a file. Appending to a file changes the file’s size, which thus incurs additional filesystem metadata operations. Instead, consider using fallocate(2) to extend the file in larger chunks
Kayce Basques: Here’s the mental leap. Embeddings are similar to points on a map. Each number in the embedding array is a dimension, similar to the X-Coordinates and Y-Coordinates from earlier. When an embedding model sends you back an array of 1000 numbers, it’s telling you the point where that text semantically lives in its 1000-dimension space, relative to all other texts. When we compare the distance between two embeddings in this 1000-dimension space, what we’re really doing is figuring out how semantically close or far apart those two texts are from each other.
Hung LeHong: The truth is that you’ve been in the mud for the last year, working hard to find all those benefits that were promised by AI, it’s not been easy.
Han Lee: This principle extends beyond corporate life and into the world of AI. Personally, I address the first group producers and the second group promoters. And in the current AI ecosystem, we’re seeing far more promoters than producers — sometimes promoters disguised as producers. This phenomenon starts at the source: academia
Martin Goodson (Super Data Science 833, 23 min): I do that think that a lot of ML research does come down to understanding data, understanding statistics, understanding the way that data can screw you over and confuse you. I've been confused so much by data, it's stayed with me to my core.
...
There's a lot of stuff that I learned in statistics that is useless now and is a waste of time. It's quite a traditional field and it hasn't moved very quickly. People are still being taught stuff that isn't really that useful, I think there should be much more emphasis on computational methods. There is a lot of stuff you can safely ignore in statistics, but you do need the approach, the attitude and skeptism about data and really understand about bias.
Martin Goodson (SDS 833, on over-hyped academia and AI, 1h12min): You could become a self-proclaimed expert quite easily by reading stuff on arXiv and you can read loads of papers, and get to become a self proclaimed expert quite easily. There are many problems, I'll highlight one, one is that the academics that are publishing this stuff are over claiming, the titles of the papers are just wildly, they don't have the evidence to claim what they're claiming. We do have people that come to the meetup and they give a talk, and they just make up stuff that is just is very over-hyped, the claims. Once you put them under scrutiny, it just falls apart. They don't have the evidence.
Helpful Humans
Christopher Winslett provides examples if different date binning methods with Postgres.
Hans-Peter Grahsl writes about schema evolution in real-time data pipelines.
Daniel Beach kicks the tires on DuckDB in Postgres and compares performance on a 50M record dataset.
Interesting topic - compute-compute separation
A week ago, Yaroslav Tkachenko expressed his enthusiam for ClickHouse Cloud’s new compute-compute separation feature. This led to us discovering some of the other systems that had introduced this architecture in the past. Let’s look now at what compute-compute separation is, and some real-world examples!
By now we’ve all heard about the benefits of compute-storage separation. The idea is that large distributed data system architectures become both simpler and more elastic. The compute layer is a stateless layer that can be scaled elastically, moved around, killed and restarted with relative abandon. The storage layer remains a tough distributed systems problem, but these days, we let the hyperscaler handle that part for us in the form of object storage.
Two quotes are relevant here:
One from Ryanne Dolan in this issue put it nicely: “The idea is you no longer need every system to be distributed and durable. Everything can be stateless and simple, cuz your storage is distributed and durable.“
One from myself, I know, shameless self-plug: “In data system design, cost is a kind of unstoppable force that rewrites architectures every decade or so, and that is happening right now. AWS, GCP and Azure have been consistent in driving down the costs and driving up the reliability of their object storage services over time. S3 et al are the only game in town and the cheapest form of storage; hence any system has to build on it and cannot really be cheaper or more reliable. You can't compete with S3 because AWS doesn't provide the primitives in the cloud to rebuild it. Your only other choice is to get some space in a co-lo and start racking your own hard drives and solid-state drives. S3 may or may not be the ideal storage interface for a diverse set of data systems from a design point of view, but in terms of economics, it is unbeatable and inevitable.“
Compute-compute separation is a logical consequence, or next step if you will, of compute-storage separation. Therefore, we can think of compute-compute separation as a shorthand for compute-compute-storage separation.
The basic idea of compute-compute separation is that we can isolate different workloads that operate over the same data, in different stateless compute pools. As long as the underlying storage can handle the aggregate load, then we get improved performance isolation as the compute-side of the workloads is running on different compute resources.
Let’s use the following definition: compute-compute(-storage) separation is the isolation of different workloads, that operate over the same data, in different stateless compute pools.
So who is doing this? I have five examples for you (though doubtless there are many more), in the order of publication:
Snowflake were the first to implement compute-compute separation (that I know of) with the design of their Virtual Warehouses (VW) that operate over object storage. Snowflake was the first to my knowledge to create a massive scale data system based on object storage. Snowflake really has been a pioneer and it’s amazing how long it’s taken the rest of the industry to catch up. Read the Snowflake paper: The Snowflake Elastic Data Warehouse (published 2016). Some choice quotes:
VWs are pure compute resources. They can be created, destroyed, or resized at any point, on demand. Creating or destroying a VW has no effect on the state of the database. It is perfectly legal (and encouraged) that users shut down all their VWs when they have no queries. This elasticity allows users to dynamically match their compute resources to usage demands, independent of the data volume.
Each user may have multiple VWs running at any given time, and each VW in turn may be running multiple concurrent queries. Every VW has access to the same shared tables, without the need to physically copy data.
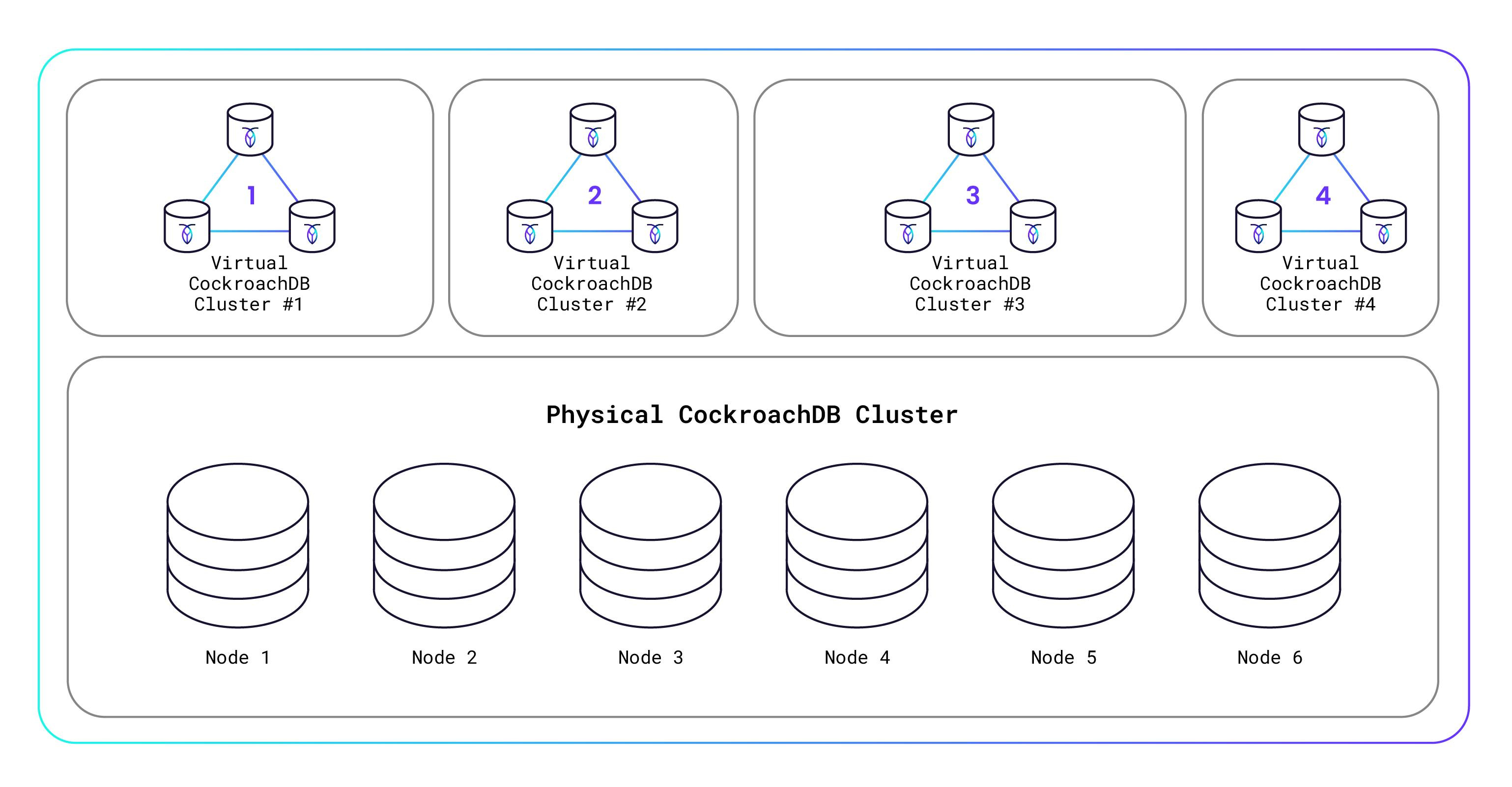
CockroachDB Serverless (2022) doesn’t use the term compute-compute separation but in fact that is exactly what it is - just applied to a serverless multitenant system. Unlike Snowflake, it does not use object storage for its storage layer, but a Raft-based replicated storage system that uses Pebble (a KV store similar to RocksDB). CockroachDB is a distributed OLTP SQL database, that stores data on disks rather than an object store, for latency reasons. However, the storage layer is a shared multitenant storage layer; the difference between this and object storage is that it is a component of CockroachDB serverless, not the hyperscaler. The compute layer is also multitenant, with each tenant operating in different Kubernetes pods with controlled resource limits. This is the compute-compute separation part, each tenant gets a slice of compute and is prevented from consuming compute resources of other tenants. Each per-tenant compute pool operates over a shared storage layer.
I wrote an extensive write-up on CockroachDB Serverless in 2023 as part of The Architecture of Serverless Data Systems.
CockroachDB also have a PDF whitepaper and a blog post.
To my knowledge CRDB Serverless doesn’t provide separate pools for the same tenant, that is, multiple pools over the same data (only the same storage). According to my own definition, CRDB Serverless doesn’t quite qualify as compute-compute separation, but given that the storage layer is shared by all tenants, I think it’s close enough. It also is an interesting case because it shows there is some diversity in these architectures.
Rockset blogged about compute-compute separation in March 2023. Rockset uses RocksDB as it’s storage layer for hot data, making it the second of my examples not to be using object storage as the primary storage layer (at least for hot data).
Warpstream blogged about Agent Groups this year, and how they allow for different consumer workloads to operate over the same Kafka topics without affecting each other. Warpstream has implemented the Kafka API over object storage.

ClickHouse in July added compute-compute separation to their docs. In their docs it says “Compute-compute separation allows users to create multiple compute node groups, each with its own endpoint, that are using the same object storage folder, and thus, with the same tables, views, etc.“



These are all examples of compute-compute separation within a single platform. But if we were to take it one level further, then we would be seeing platform-platform(-storage) separation. This is another trend that is brewing with the rise of both Iceberg et al and also DuckDB (that is being inserted into more and more places).
On this last topic, I’ll leave you with this quote:
The not-so-subtle undertone of the "small data" and duckdb.org movement is decentralized analytics. Magic truly happens when compute/storage are separated but then also decentralized. — Jake Thomas